An agent without memory isn't really an agent. It's a function that forgets everything the second it answers you. Fine for a one-shot question. Useless for anything that takes more than one step.
So the real question isn't whether your agent needs memory. It's what kind.
Right now there are two serious answers: vector databases and graph RAG. And most teams don't really choose; they reach for a vector DB on reflex, embed everything, and move on. I think that's the wrong call more often than people admit. Here's how I actually think about it.

Vector databases: fast, fuzzy, and that's fine
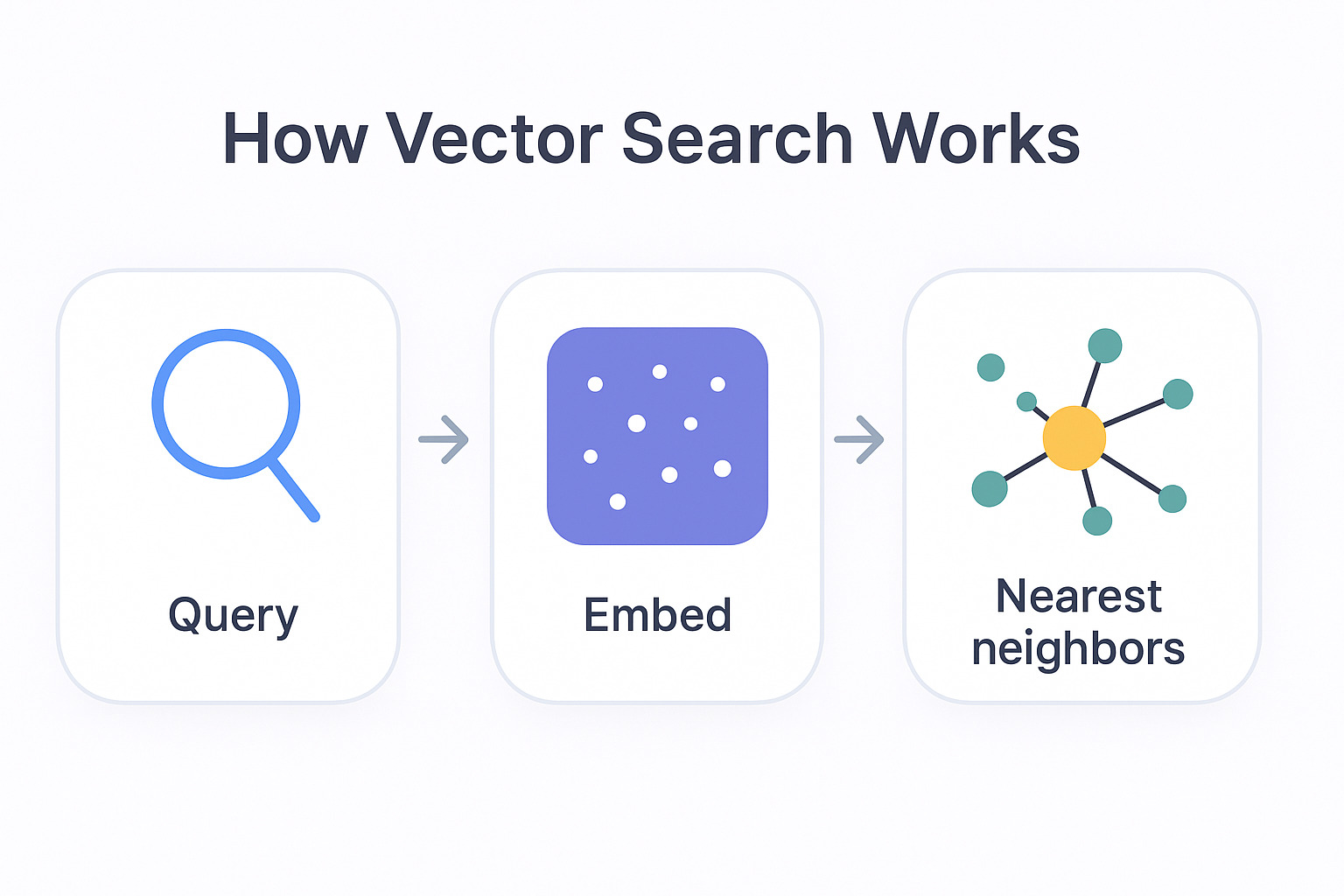
A vector database turns text into coordinates. Things that mean similar things end up near each other. You ask a question, it grabs whatever's nearby. That's the whole trick.
And honestly, for a lot of work that's plenty. Chat history. Docs. Loose notes. Code you half-remember writing. You don't need precision there, you need "find me the stuff that's roughly about this." Vector search nails it. It shrugs off typos and weird phrasing, and you can stand one up in an afternoon.
Here's where it falls apart.
Vector search doesn't reason. It matches. If the answer lives across a few hops (A relates to B, B relates to C, so A affects C), similarity search will usually miss it. Nothing in the embedding knows those things are connected. They're just two dots that happen to sit far apart.
And the denser your data, the worse it gets. Org charts. Dependency trees. Approval chains. Ask a vector DB about those and you get back a pile of stuff that's related but not right, stuffing your context window with noise the model then has to dig through.
Graph RAG: more work up front, much harder to fake
Graph RAG flips it. Instead of "what's nearby," it asks "what's actually connected." Entities become nodes. Relationships become edges: approved by, depends on, reports to. The agent walks the connections instead of guessing at them.
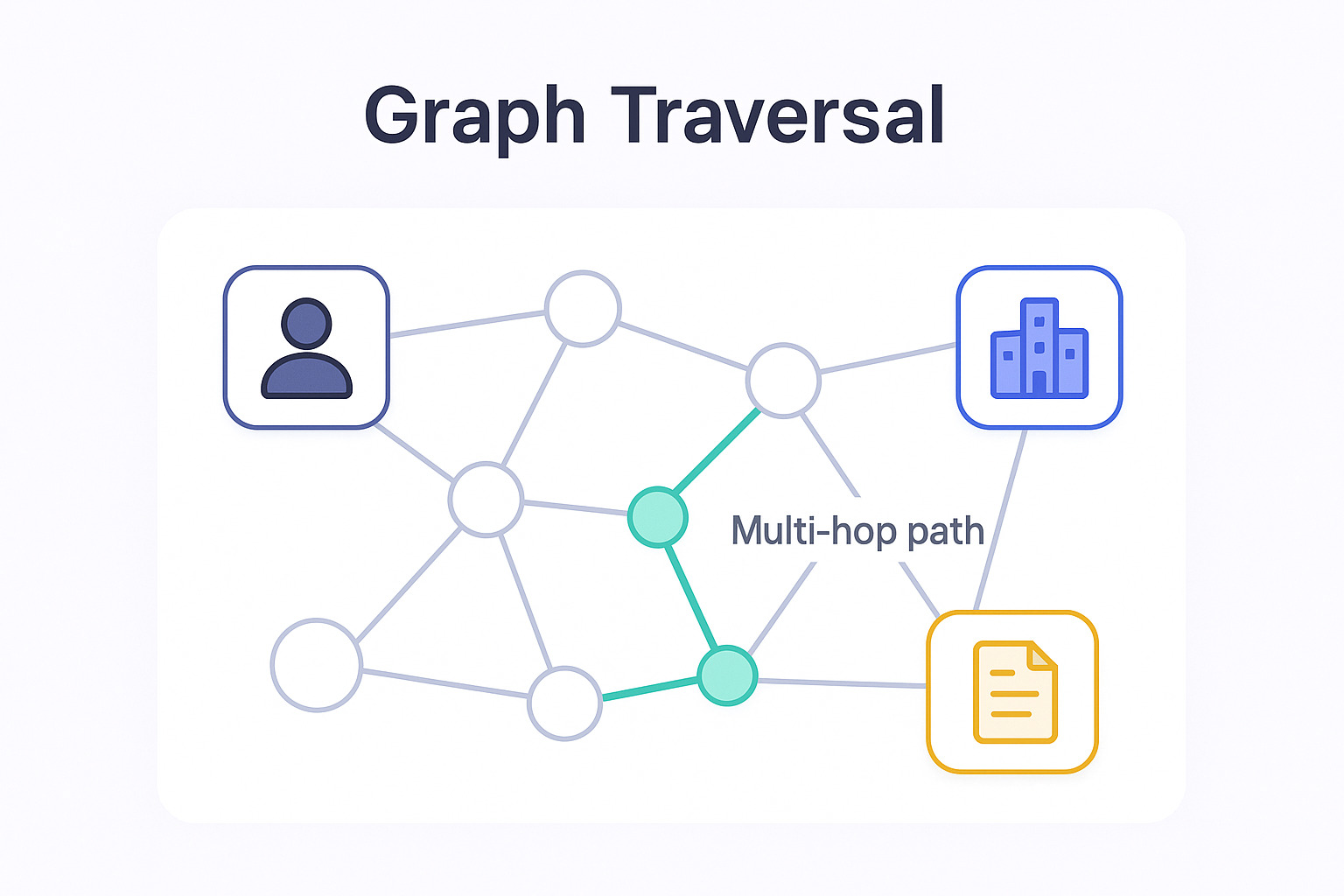
The payoff is precision. If a relationship isn't in the graph, the agent won't invent one. "Who reports to the manager that signed off on this budget?" is one clean walk through the graph, and a small nightmare for vector search.
But the part I care about most: you can show your work. The path the agent took is just a list of nodes and edges. Not a similarity score nobody can interpret, but an actual trail you can hand to an auditor and defend. In regulated work that isn't a nice-to-have. It's the whole game.
The catch is it's real work. You have to pull entities and relationships out of messy text reliably, design a schema, and keep evolving it. And a fresh graph knows nothing until you fill it, there's no "embed and go." A vector DB is useful on day one. A graph earns its keep later.
So which one?
Let the data and the questions decide. Not the hype.
Go with vector search when the data is loose and the questions are vague. "What did we say about X?" "Find me things like this." Notes, docs, transcripts, sprawling knowledge bases. Cheap to build, good enough to ship, the right default for a prototype.
Go with graph RAG when the data has real structure and the answer has to be exact. "How is X connected to Y?" "What breaks if I change this?" Financial records. Code dependencies. Control frameworks. Anywhere a confident-but-wrong answer actually costs you something.
The honest answer is usually "both"
The best setups don't pick. They layer.
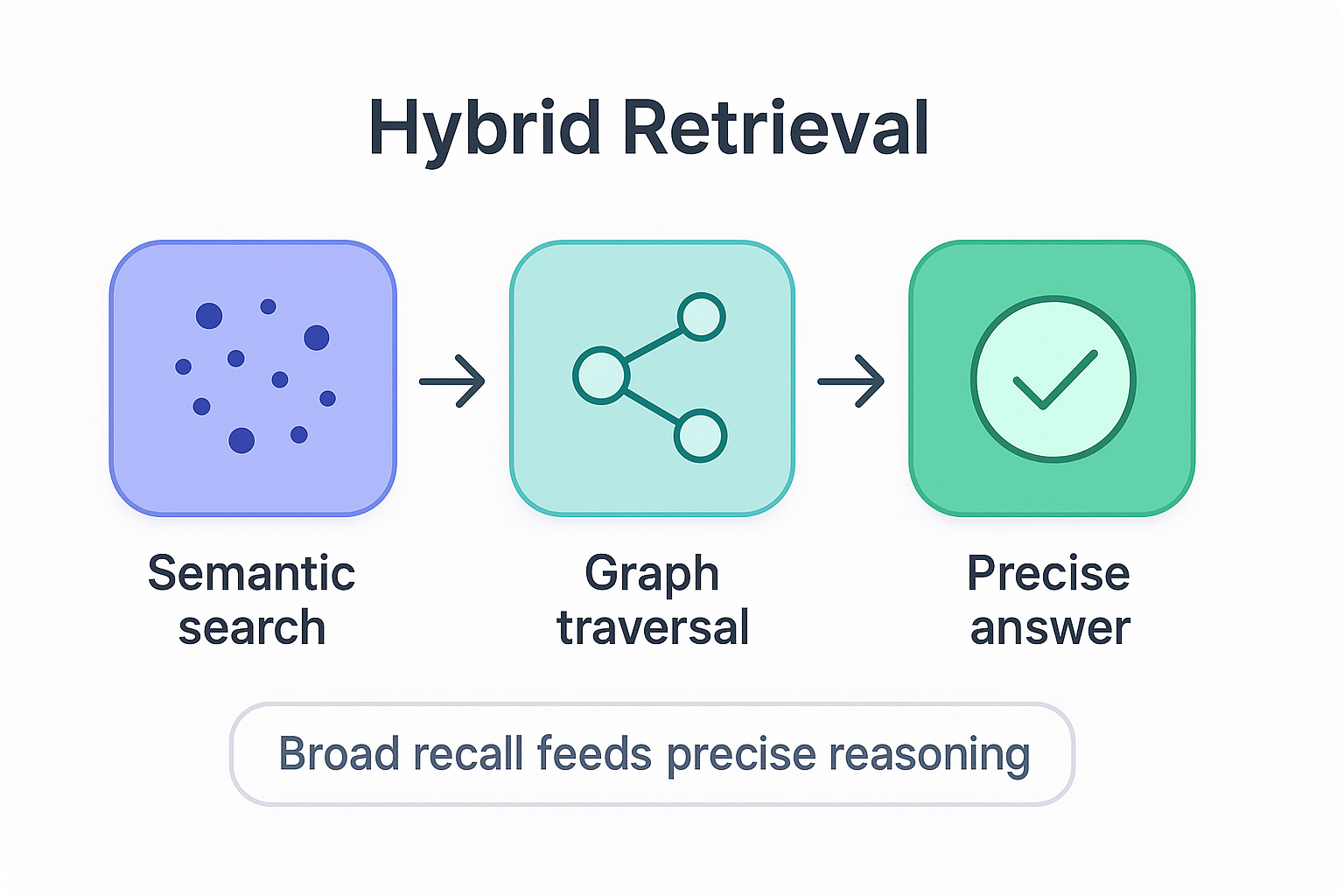
Use the vector DB to find the door: a fast semantic search to land on the right entry points in a big graph. Then switch to graph traversal to pull the exact relationships hanging off those nodes. Fuzzy recall to get close, hard structure to get it right.
That's where I land most of the time. Start with a vector database, because it gets you moving. Add a graph the moment "close enough" stops being good enough, and in regulated work, that moment comes early. When the answer has to be precise, traceable, and defensible, the graph isn't an upgrade. It's the part that lets you stand behind what your agent just did.