Executive Summary
A localization team needed to translate a lot of content, into a lot of languages, without choosing between speed and trust. Translating everything by hand was too slow and too expensive. Letting raw machine translation ship was a non-starter for content where a mistranslation carries real cost.
The answer was not "AI instead of people." It was AI first, people in charge. The system lets AI do the heavy lifting of a strong first draft, then routes every result to expert reviewers who certify it, and it remembers every decision so the same work never gets paid for twice.
In practice that meant a pipeline moving on the order of hundreds of thousands of translatable segments across 25-plus target languages, where the AI first pass arrives in seconds and a reviewer certifies it in a fraction of the time a from-scratch translation would take.
AI first pass. Human certified. Built on translation memory.
Where Things Stood
Before the engagement, the program ran the way most enterprise localization runs: a roster of vendors and freelance linguists, work handed off by email and spreadsheet, and turnaround measured in weeks. A single product release could fan out into dozens of language pairs, each one a separate negotiation over cost and schedule.
There was a translation memory, but it lived inside individual vendor tools and rarely came back. Glossaries existed as static documents that nobody opened mid-task. The same product name might be translated three different ways in three different markets, and no one noticed until a customer did.
The team had already experimented with raw machine translation to cut cost. The output was fast and cheap and occasionally wrong in ways that were expensive: a flipped negation here, a tone that read as rude in-market there. The lesson was not that machine translation was useless.
Machine translation without ownership was a liability.
The System at a Glance
Content flows through four stages: ingestion, an AI translation pipeline, a human review and certification workflow, and publishing, with a translation memory underneath that every stage reads from and writes back to.
The design goal was a single system of record. Instead of work scattering across vendor tools and inboxes, every segment, every decision, and every approval lives in one place where it can be measured, reused, and audited.
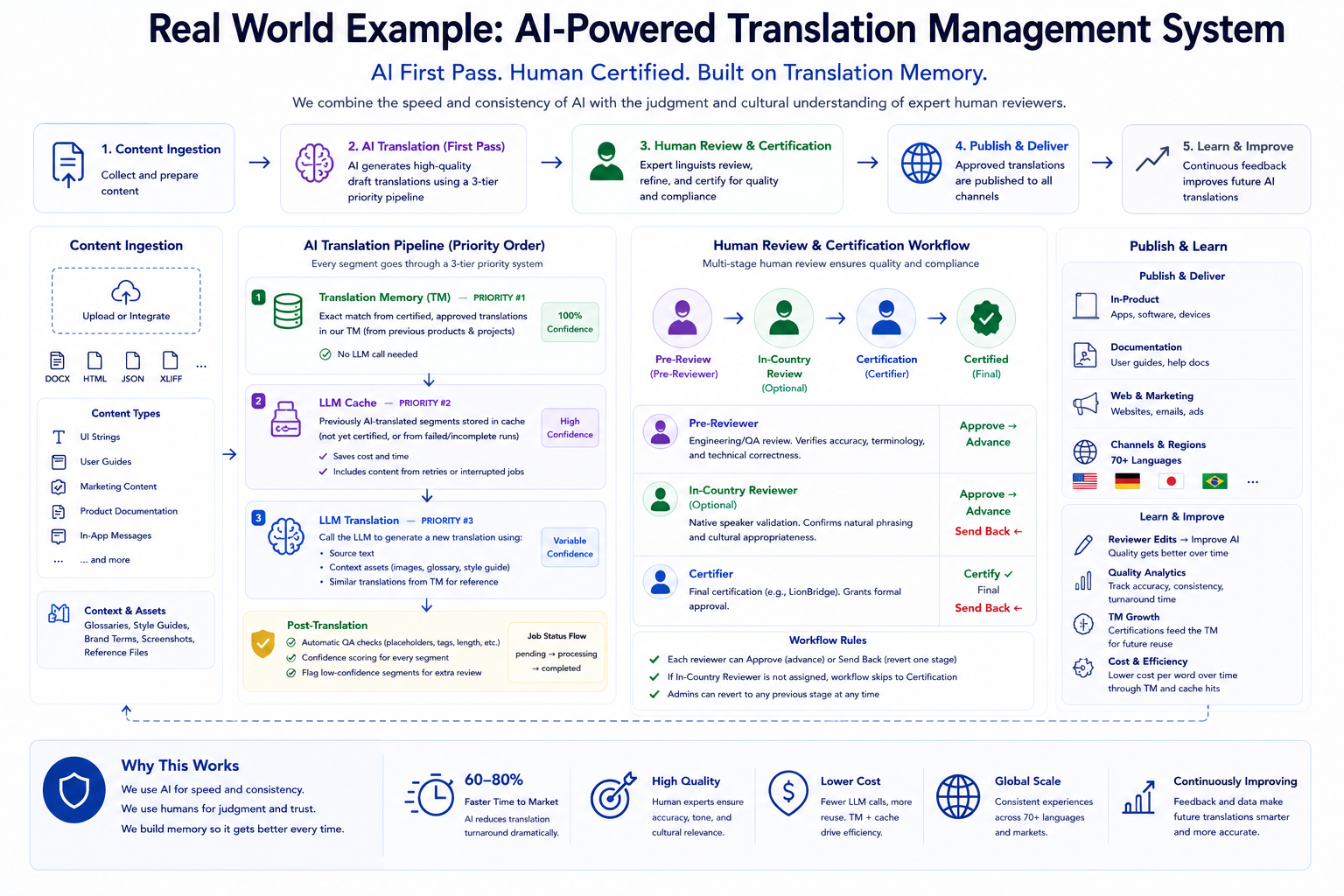
1) Content Ingestion
Everything starts with context. Content is uploaded or pulled in through an integration, tagged by type, and paired with the spec, glossary, and reference material a translator would need. Nothing goes into the pipeline as bare text.
Ingestion also does the unglamorous work that makes everything downstream possible: it strips and stores formatting, segments the content into translatable units, and matches each unit against the translation memory before a model is ever called. By the time a segment reaches the pipeline, the system already knows whether it has seen this sentence before.
- Upload or integrate content directly from source systems
- Classify by content type and target languages
- Attach context, specs, and reference material up front
- Segment content and preserve formatting metadata for later reassembly
- Pre-match every segment against translation memory and glossary
- Route through a priority queue so urgent work moves first
2) The AI Translation Pipeline
The pipeline runs in priority order, and the order matters. It does not reach for the model first. It reaches for what is already approved.
Translation memory comes first: anything that has been translated and certified before is reused exactly, for free. On mature content, exact and high-fuzzy matches alone can resolve 30–50% of a document before the model sees a single word. Only the genuinely new content goes to the model, and even then it is grounded in the glossary, terminology, and cultural-adaptation rules so the first pass reads like a person wrote it, not a dictionary.
For the remaining content, the model is prompted with the surrounding context, the relevant glossary entries, and any nearby fuzzy matches as worked examples. That grounding is the difference between a generic translation and one that already speaks in the brand voice. A typical first pass returns in seconds per segment, fast enough that reviewers are never waiting on the machine.
- Translation memory reuse: approved segments are applied first, at no cost
- Pre-translation fills in the high-confidence fuzzy matches
- LLM cultural adaptation handles tone, idiom, and locale
- Glossary and terminology enforcement keeps language on-brand
- Context window includes specs, reference text, and nearby matches
- Fast or full translation depending on priority and risk
3) Human Review & Certification
This is the part that makes the output trustworthy. The AI never has the last word. Every result lands in front of expert reviewers whose job is to certify it: judgment, cultural nuance, and accountability that a model cannot provide.
Because reviewers are checking a strong draft instead of translating from a blank page, they move far faster than traditional translation while staying the authority on what ships. In practice a reviewer can certify several times the daily word count of a from-scratch workflow, and the segments they touch most are the new ones, the memory has already handled everything that was settled before.
The interface is built around the review, not the typing. Confidence scores, glossary hits, and the original source sit side by side, so a reviewer can confirm a high-confidence segment in a glance and spend their attention where it actually matters.
- Pre-review screening flags anything low-confidence for closer attention
- Expert reviewers correct and approve the AI draft
- Source, draft, glossary, and confidence shown side by side
- In-country reviewers confirm cultural and regional fit
- Edit distance tracked per segment to measure first-pass quality
- Certification and QA gate the content before it can publish
4) Publish, Deliver & Learn
Once certified, the formatting is restored and the content is delivered to the right channels and regions. Analytics and reviewer feedback flow back in, and, critically, every certified translation is written back into the memory.
That is the compounding loop. The next document that contains the same sentence does not pay for it again. The system gets cheaper and more consistent with every job it finishes.
The loop also surfaces patterns. When reviewers repeatedly correct the same term, that correction becomes a glossary update, which improves the next first pass automatically. The system is not just remembering translations, it is learning the program house style and applying it before a human has to ask.
Under the Hood: Technical Architecture
The system is built around a segment-level data model. Every translatable unit carries its source text, target translations per language, status, confidence, edit history, and links to the glossary terms and memory matches that informed it. That granularity is what makes both reuse and auditing possible.
A large language model handles the cultural-adaptation pass, called through a routing layer that picks a faster or fuller model depending on the priority and risk of the content. The translation memory is stored for fast similarity lookup so exact and fuzzy matches return instantly. A queue coordinates the pipeline so urgent work jumps ahead without starving the rest.
Integrations let content flow in and out of the source systems the team already uses, so the management system becomes the hub rather than yet another silo. Nothing about the architecture forces a rip-and-replace; it sits alongside existing tools and gradually becomes the place the work actually lives.
- Segment-level data model with full status, confidence, and edit history
- Model routing layer selects speed vs. depth per job
- Translation memory tuned for fast exact and fuzzy lookup
- Glossary service enforced at translation and review time
- API integrations with source content systems for intake and delivery
Rollout: From Pilot to Production
The program did not switch over all at once. It started with a single content type in a handful of languages, run in parallel with the existing process so the two could be compared honestly on quality and turnaround.
Once the AI first pass plus certification was demonstrably matching the quality of the old workflow at a fraction of the time, the rollout widened: more languages, more content types, and deeper integration into the release pipeline. Reviewers were brought in early and helped shape the interface, which mattered: the people certifying the output trusted a system they had a hand in shaping.
By the time it reached production scale, the translation memory had enough certified material in it that new work routinely arrived partly pre-translated, and the cost-per-word curve had started its steady decline.
Challenges & Trade-offs
The hardest problems were not about the model. They were about trust and consistency. Reviewers had to believe the first pass was worth certifying rather than redoing, and that trust was earned by making the system transparent: showing why each segment was translated the way it was, and never hiding a low-confidence guess as a confident answer.
Terminology was the other recurring battle. A glossary is only useful if it is enforced, and enforcement has to be smart enough to handle inflection and context rather than blind find-and-replace. Getting that balance right took iteration with the in-country reviewers who knew where the rules genuinely applied and where they did not.
There was also a deliberate trade-off in speed versus depth. Not every piece of content deserves the fullest, most expensive translation pass. The routing layer exists precisely so that high-risk content gets the careful treatment and routine content moves fast, instead of paying premium effort on everything.
Why It Works
The mechanism is the division of labor. AI does what it is good at: a fast, consistent first pass at scale. People do what they are good at: judgment, nuance, and standing behind the result. The translation memory makes sure neither side ever repeats work.
AI carries 80–90% of each document. Reviewers certify rather than start over, so quality stays high and cost and turnaround drop. And because every approval feeds the memory, the system improves continuously: global scale without giving up the human accountability that high-stakes content demands.
The roadmap from here is more of the same compounding: richer per-domain glossaries, tighter integration so newly authored content is queued for translation the moment it is written, and confidence models good enough to let the safest segments auto-certify while humans concentrate on the rest. The destination is not full automation. It is humans spending all of their judgment exactly where judgment is needed.
The value is not AI translation. It is the division of labor.
Results
- AI handles 80–90% of each document on the first pass
- Reviewers certify instead of translating from scratch, roughly 3-4x faster throughput
- Translation memory compounds: every approval lowers future cost
- Cost per translated word trending down quarter over quarter