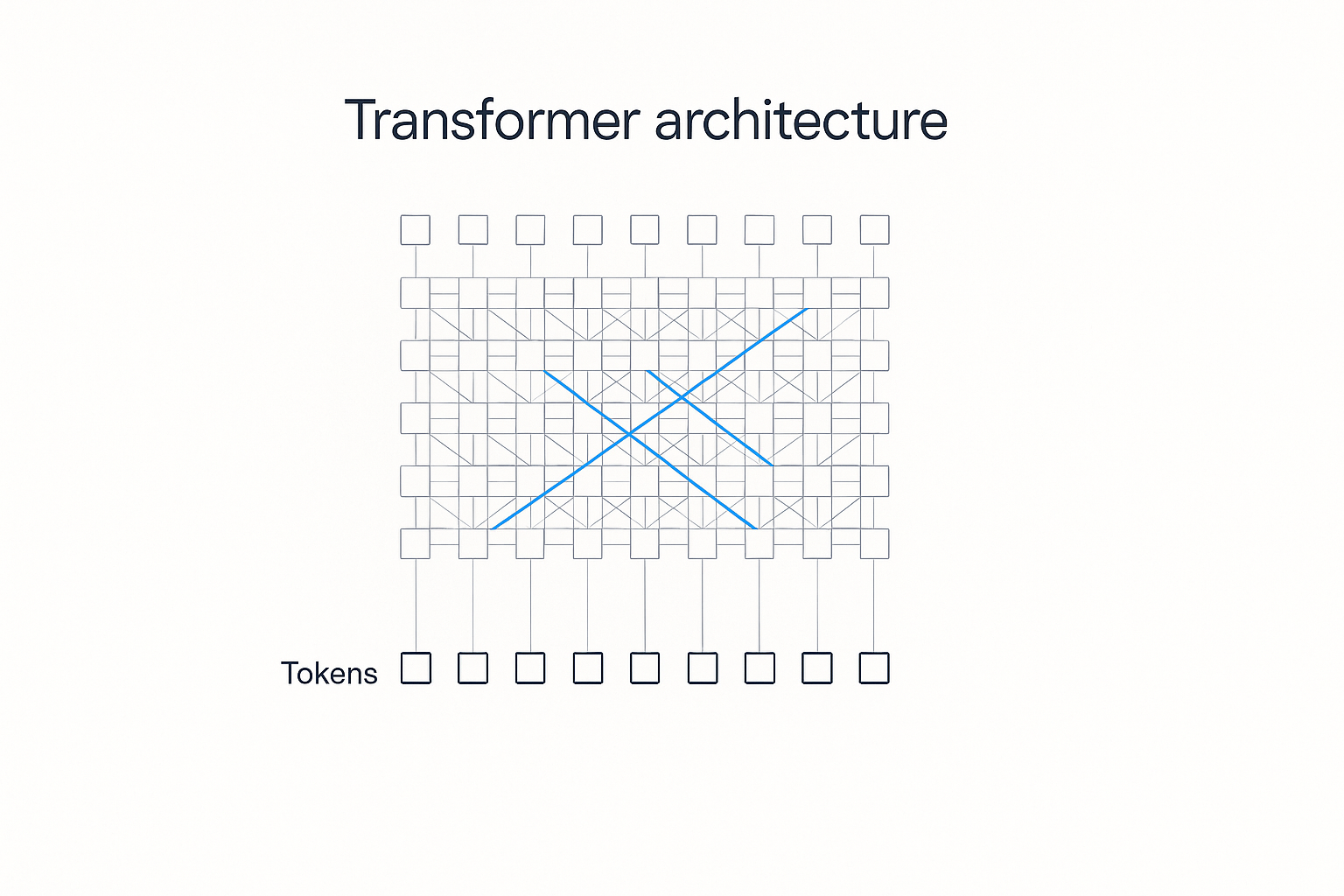
The transformer is the thing under the hood of basically every AI you've heard of. The "GPT" in ChatGPT stands for Generative Pre-trained Transformer. It's the idea that kicked off the whole era.
And you can understand it without a single equation. The math is how it's built; it's not what it does. What it does comes down to three moves: chop the text into pieces, turn each piece into coordinates, and let the pieces look at each other. Chop, place, look. That's the transformer.
If you haven't read the first piece, the one thing to carry over is this: the whole machine exists to predict the next word. Everything below is in service of that.
Move one: chop the text into tokens
The model doesn't see words. It sees tokens, chunks of text, often a word, sometimes a piece of one.

Why not just use words? Because language is messier than a dictionary. There are made-up words, typos, names, code, emoji, six languages. If the model only knew whole words, the first unfamiliar one would stop it cold. So instead it learns a vocabulary of useful fragments. Common words get their own token. Rarer ones get built from pieces: "tokenization" might split into "token" and "ization." With a few tens of thousands of these fragments, it can spell out almost anything, including words it never saw in training.
This is also, quietly, why models charge by the token and why they have limits measured in tokens. Tokens are the actual unit the thing reads and writes. Words are just what we see.
Move two: turn tokens into coordinates
Here's the move that makes meaning possible. Each token gets turned into a list of numbers, a position in space. This is called an embedding, and it's the heart of the whole thing.
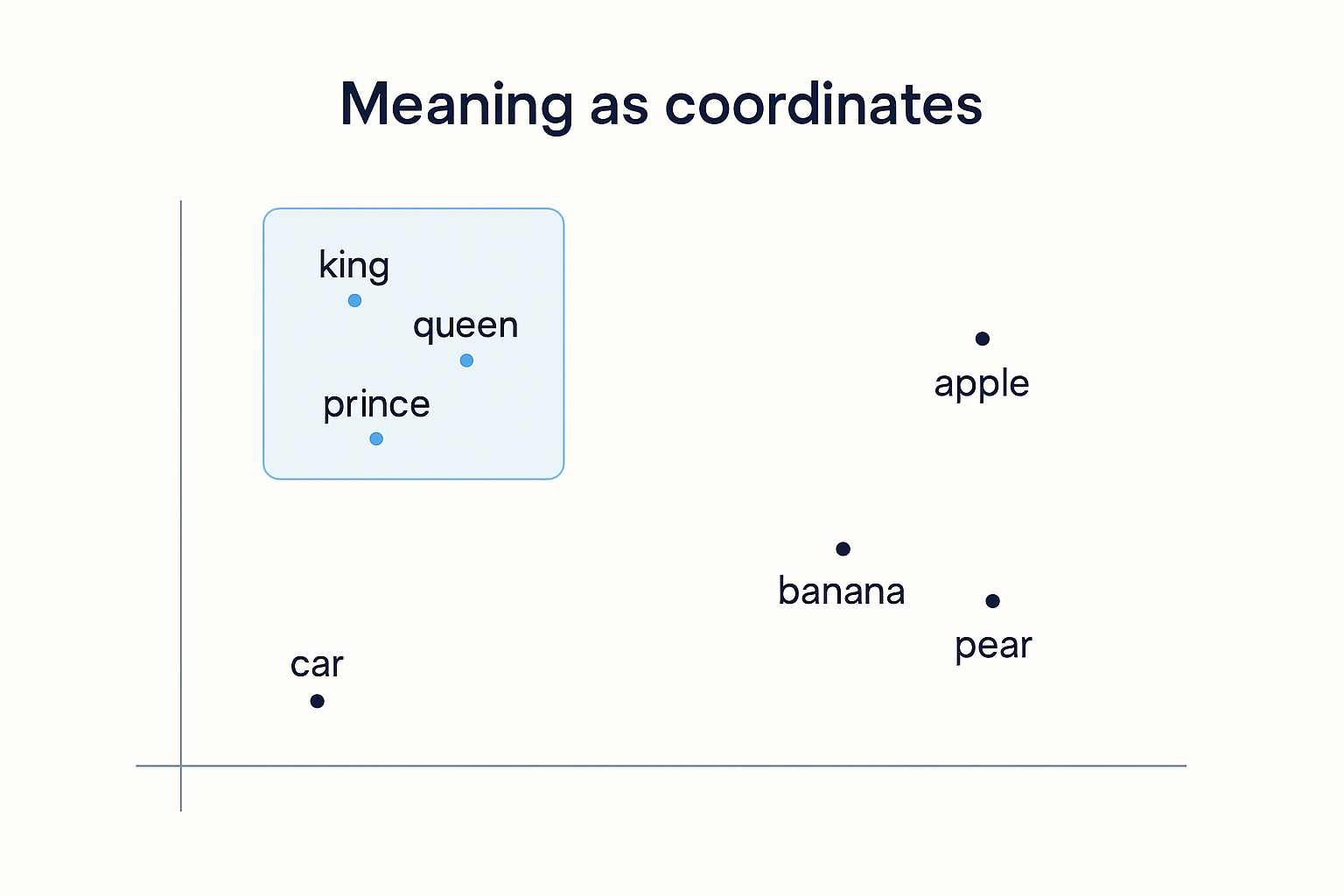
Picture a giant map where every word has a location. The trick is that words with related meanings end up near each other. "King," "queen," and "prince" land in the same neighborhood. "Apple," "banana," and "pear" cluster somewhere else entirely. "Car" sits off on its own.
The model isn't told to do this. It falls out of training. Words that show up in similar contexts drift toward similar coordinates, because that's what helps predict the next word. And once meaning is just position, the model can do something almost eerie: arithmetic on concepts. The classic example: take "king," subtract the direction that separates men from women, and you land near "queen." Meaning becomes geometry. That's the leap. The model stopped pushing symbols around and started working in a space where distance means relatedness.
Move three: let the words look at each other
Tokens placed as coordinates still aren't enough, because words change meaning depending on their neighbors. "Bank" by a river is not "bank" with your money. The model needs to read each word in context. That's attention, and it's the move the transformer is named for.
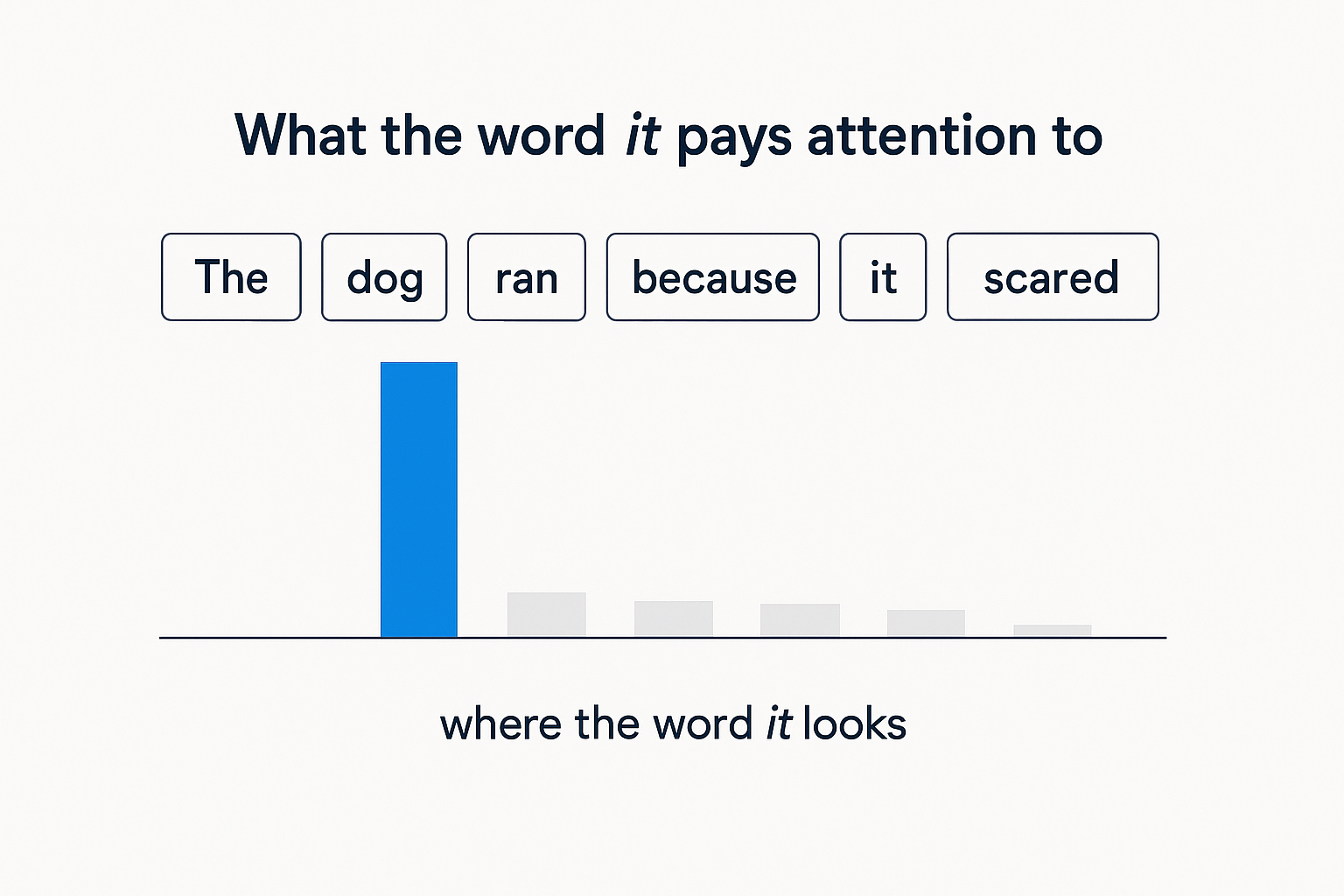
Attention lets every word look at every other word and decide which ones matter to it right now. Take "The dog ran because it was scared." What does "it" mean? You know instantly: the dog. For a machine that's a genuine puzzle, nothing in the grammar alone says "it" can't point somewhere else. Attention is how the model resolves it. When processing "it," it looks back across the sentence and puts most of its weight on "dog." It learned, from mountains of text, that this is the kind of sentence where "it" refers to the subject.
Now multiply that by every word looking at every other word, all at once, in parallel. That's the superpower the older left-to-right models didn't have. Nothing has to wait its turn, and nothing gets forgotten by the end of a long passage. Every word is read in the full light of every other word.
Stacking it up
One round of look-at-each-other is good. Modern models do it dozens of times in a stack of layers.
The intuition for the stack: early layers catch the small, local stuff: grammar, which word modifies which. Middle layers assemble meaning: who did what to whom. Later layers handle the big picture: tone, intent, where this is all going. Each layer hands a richer understanding up to the next, the way you'd read a sentence, then a paragraph, then grasp the argument.
After the last layer, the model takes everything it now understands about the text so far and does the only thing it was ever built to do: predict the next token. Then it adds that token to the input and runs the whole stack again for the next one. Chop, place, look, over and over, one token at a time. A whole essay is just that loop, spinning fast.
Why this matters beyond trivia
It's tempting to file all this under "nice to know." It isn't, if you actually depend on these systems.
Knowing it's tokens explains why a model miscounts the letters in a word, it never saw the letters, only the chunk. Knowing meaning is position explains why models are brilliant at "things like this" and shaky on precise, exact lookups: distance is fuzzy by design. Knowing attention is doing the heavy lifting explains why how you phrase a prompt changes the answer so much: you're nudging what the words pay attention to.
The architecture isn't an implementation detail. It's the grain of the wood. Work with it and these tools feel like magic. Work against it and you'll keep getting surprised. Last in the series: how a raw transformer becomes a helpful assistant, and why it still gets things wrong.