A fresh transformer is not a helpful assistant. It's a brilliant parrot. It can finish your sentence in a hundred styles, but ask it a question and it's as likely to reply with three more questions, because on the internet, questions are often followed by more questions. It learned the pattern, not the job.
Turning that parrot into something that actually helps takes three distinct stages. Knowing them is the clearest way I know to understand what these models are good at, what they're bad at, and (the part everyone asks about) why they make things up with such a straight face.
This is the last of three. The earlier pieces covered what an LLM is and how the transformer works. Here's how one gets trained.
The three stages
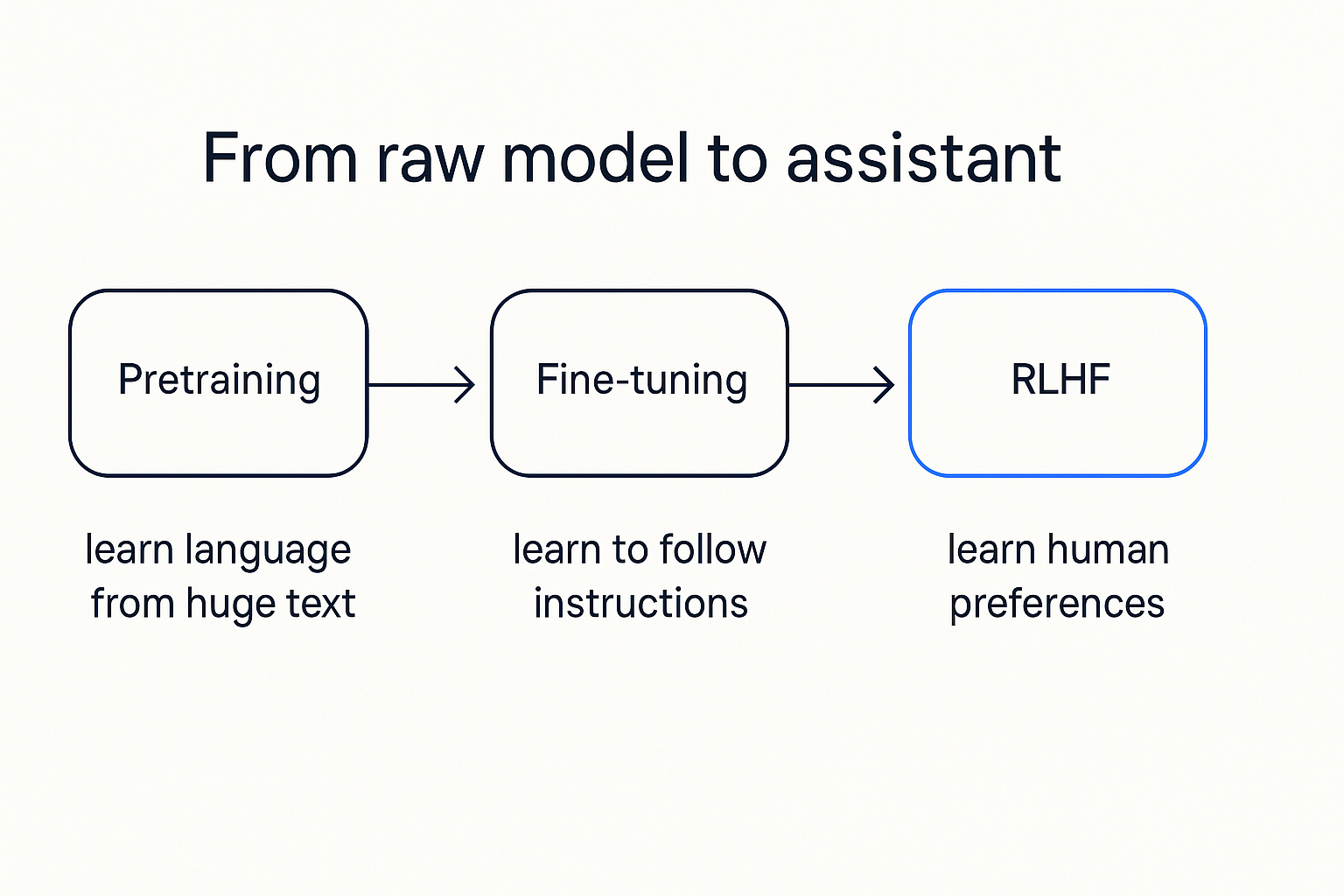
Stage one: pretraining. This is the big, expensive one. You take the raw model and feed it an enormous slice of the internet, books, code, and have it play the next-word game, trillions of times. Each miss nudges its internal numbers a hair. Do that long enough and the model soaks up grammar, facts, reasoning patterns, coding, a sketch of how the world tends to work. This is where the raw capability comes from, and it costs millions of dollars and months of compute. At the end you have something that knows an astonishing amount and is still useless to talk to. It completes text. It doesn't help.
Stage two: fine-tuning. Now you teach it the job. You show it tens of thousands of examples of the behavior you want: a question, then a good answer; an instruction, then it being followed. The model already knows language cold; here it's just learning the shape of being an assistant. Respond when asked. Follow the instruction. Be useful instead of merely plausible. This is where the parrot learns it's supposed to answer.
Stage three: RLHF. Reinforcement learning from human feedback, the polish. People look at pairs of answers and pick the better one, over and over. That preference signal trains the model toward responses humans actually prefer: clearer, more helpful, less likely to say something toxic or unhinged. This is the stage that makes a model feel considerate rather than just correct. It's also where a lot of the guardrails get set, and where reasonable people argue about who decides what "better" means.
Three stages, three different things. Pretraining builds the brain. Fine-tuning gives it a job. RLHF teaches it manners. Skip any one and it shows.
The catch nobody mentions: it only sees a window
Before the failure modes, one structural fact that explains a surprising amount of weird behavior.
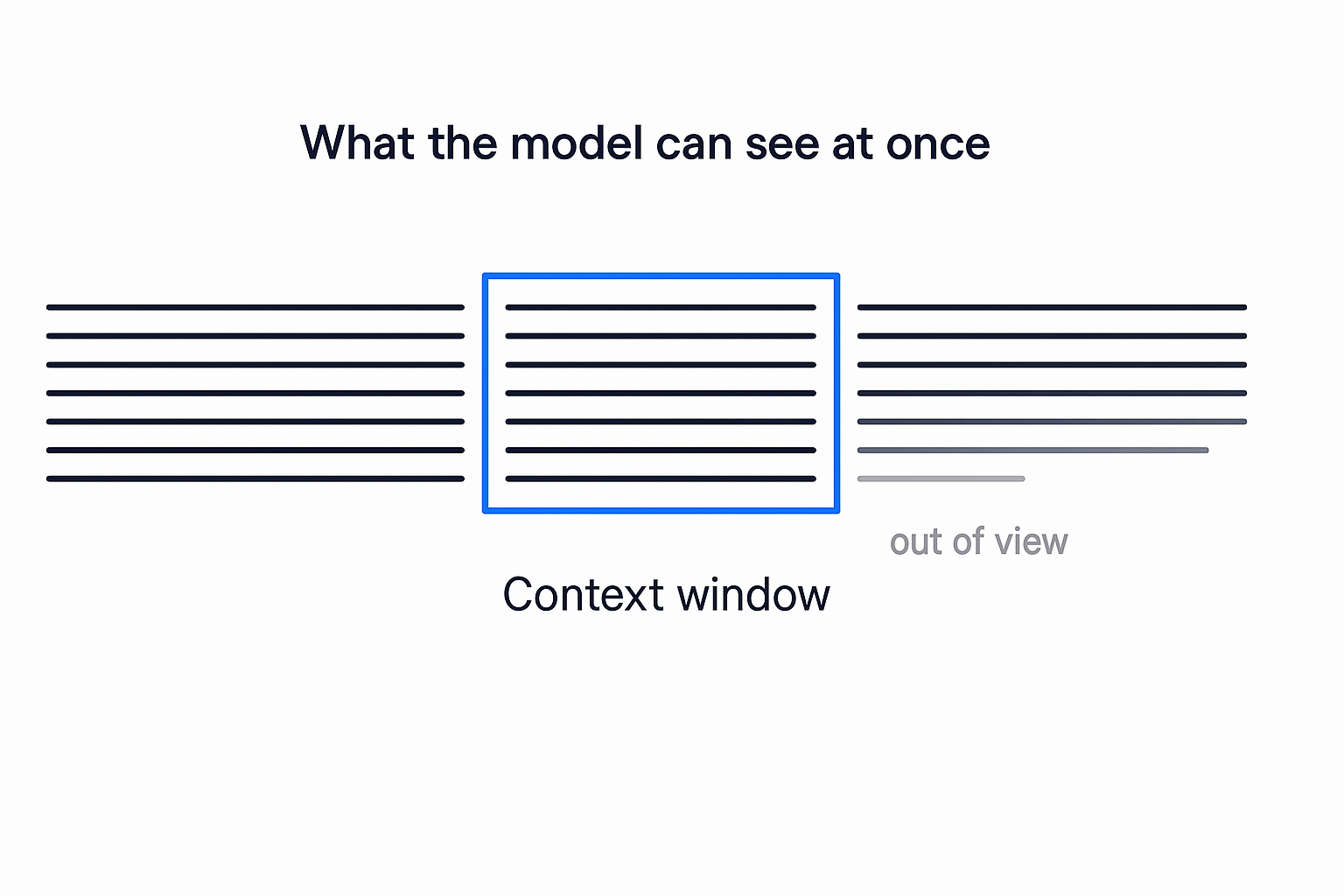
A model has no memory between conversations and a strictly limited memory within one. Everything it can consider right now (your prompt, its instructions, the chat so far) has to fit inside its context window. Think of it as how much the model can hold in its head at once. Push past the edge and the oldest stuff falls out of view. Gone.
This is why a long chat starts forgetting what you said at the top. Why pasting a huge document and asking about page one can flop. Why "remember this for later" only works until "later" scrolls off the edge. The model isn't being lazy. The earlier text is literally no longer in front of it. There's no separate memory it can go retrieve from, only the window. (Tricks like retrieval and external memory exist precisely to work around this, but the raw model's reach ends at the window.)
Why it makes things up
Here's the one everyone wants explained. Why does a model state something completely false with total confidence?
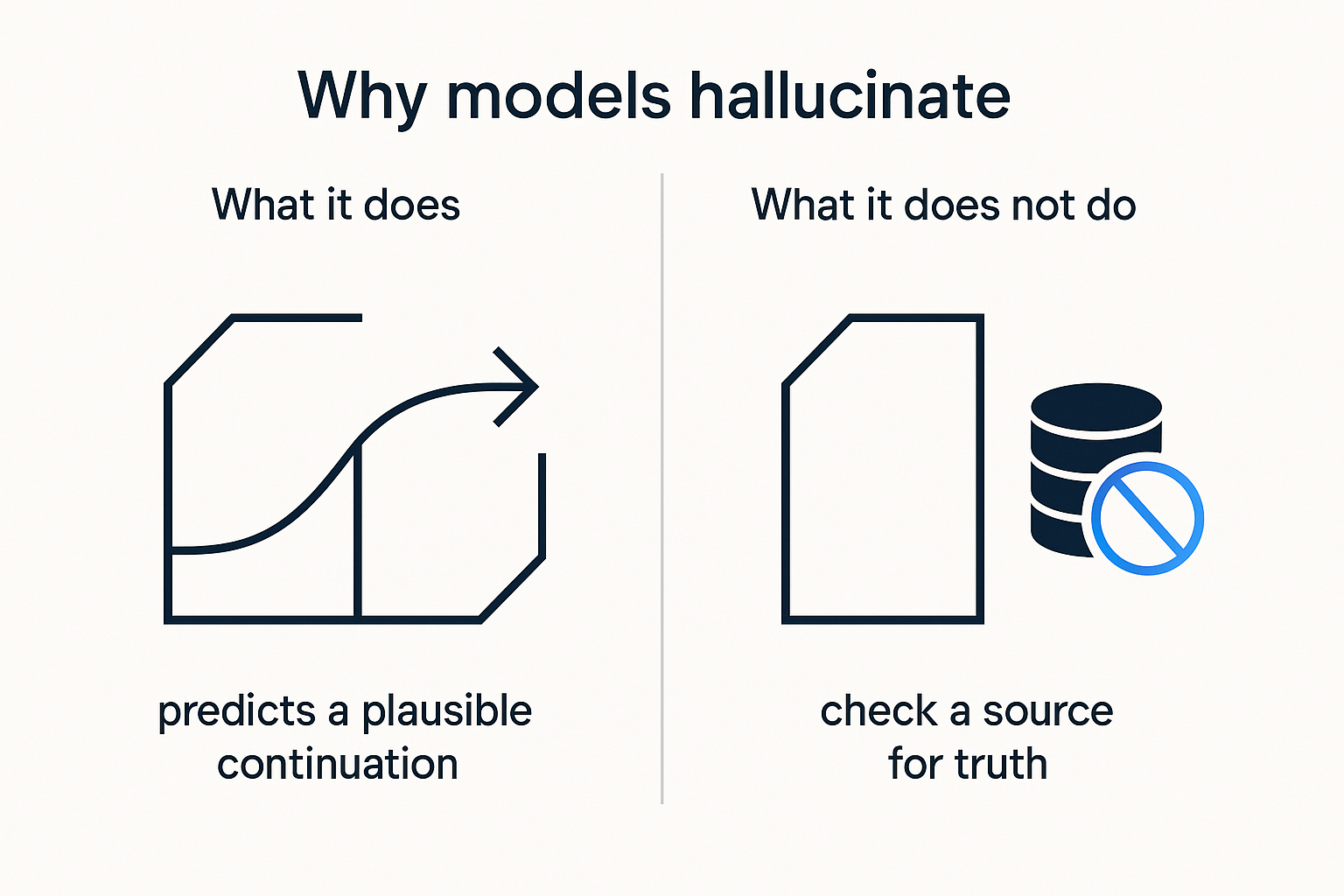
Go back to the core idea from part one: the model predicts plausible continuations. That's all it does. It is not looking anything up. It has no internal fact-checker, no little voice that says "are you sure?" When you ask for a citation, it generates text shaped like a citation (plausible author, plausible title, plausible year), because that's what citations look like. Whether that paper exists is a question the model never asked, because checking truth was never part of the job. It only ever learned what's likely, and a convincing fake is, by construction, likely.
So hallucination isn't a glitch they'll patch away next quarter. It's the flip side of the exact thing that makes the model useful. The machinery that confidently tells you the capital of France is the same machinery that confidently invents a court case. It cannot tell the two apart, because from the inside they're identical: both are just high-probability completions. The model is equally sure of both, because "sure" isn't really something it has.
This is the part that matters most for serious work, and it's where I'll connect this back to everything we do. In a casual chat, a made-up fact is a shrug and a correction. In finance, healthcare, law, anywhere a wrong answer carries real weight, a confident fabrication is a liability wearing the costume of an answer. That's not a reason to avoid these models. It's the reason you wrap them in the right scaffolding: retrieval so answers are grounded in real sources, verification so claims get checked, human review where the stakes demand it, and a hard rule that the model's confidence is never treated as evidence it's right.
That's the honest picture. A next-word predictor, trained in three stages into something genuinely useful, that reasons impressively and fabricates just as fluently, and has no idea which it's doing. Understand that, and you'll use these tools better than most. You'll lean on them where they're strong, never trust them blind, and build the checks that turn a brilliant, unreliable parrot into something you can actually stand behind.