People talk about large language models like they sat down and learned to understand English. They didn't. What's going on inside is stranger than that, and also a lot simpler. Once it clicks, most of the mystery, and a fair amount of the hype, falls away.
This is the first of three plain-English pieces. No math, no jargon you have to pretend to follow. Just the actual idea. If you've ever wanted to know what's really happening when you type a question into a chatbot, start here.
The one sentence that explains most of it
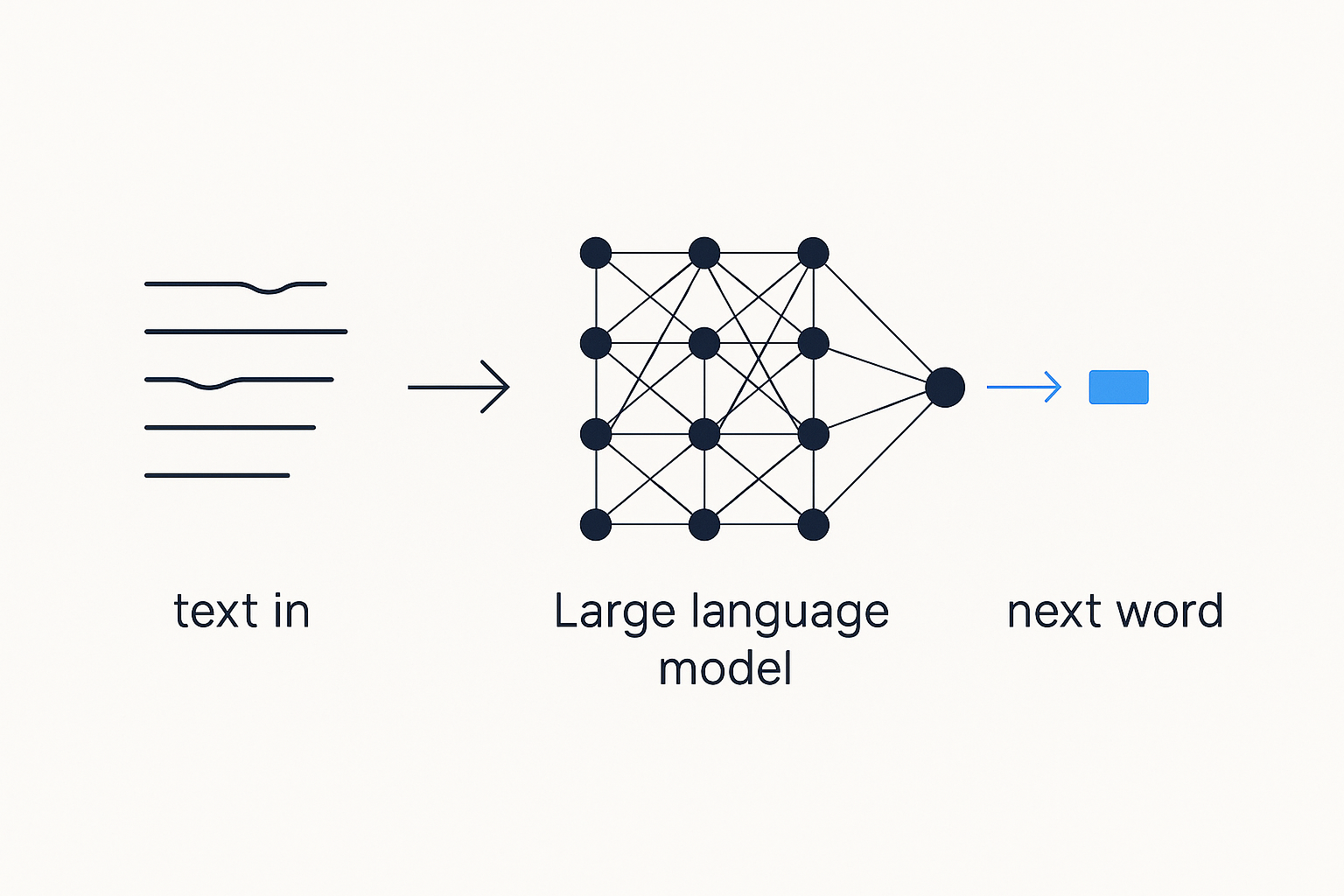
An LLM is a machine that predicts the next word.
That's it. That's the whole engine. You give it some text, and it asks itself one question: given everything so far, what word probably comes next?, picks one, adds it, and asks again. Word by word, that's how a paragraph comes out.
I know how underwhelming that sounds. "It's autocomplete" is the most deflating possible description of something that can write a sonnet or debug your code. But it's true, and holding onto it will save you from a hundred wrong intuitions about what these things can and can't do.
The interesting part isn't the prediction. It's what a model has to figure out to get good at it.
How we got here
We didn't start with prediction. We got there the long way.

The first crack at language AI was rules. Armies of people writing if-this-then-that grammar by hand. If the sentence looks like X, do Y. It worked for tiny, tidy problems and shattered the moment real language showed up, because language doesn't follow the rules we'd write down. There are too many exceptions, and the exceptions have exceptions.
Then came statistical machine learning. Instead of writing the rules, you let the machine count. Feed it enough text and it learns that "strong tea" is common and "powerful tea" is not, without anyone explaining why. Better. But still shallow: it saw words as beads on a string, with almost no sense of meaning.
Neural networks went deeper. Loosely inspired by how brains pass signals between neurons, they could learn fuzzier, richer patterns. Real progress, but the early ones read strictly left to right and forgot the start of a long sentence by the time they reached the end. Ask one about the beginning of a paragraph and it had already lost the thread.
Then in 2017 came the transformer, and everything jumped. Its trick was letting the model look at all the words at once and work out which ones matter to each other, so "it" in a long sentence can reach back and connect to the noun it refers to, twenty words ago. That one capability is what turned a next-word predictor into something that feels like it's reasoning. We'll pull that apart in the next piece.
"Predict the next word" sounds dumb. It isn't.
Here's the part that flips the whole thing around.
To predict the next word well, across billions of sentences about everything, you can't just memorize. There's not enough memory in the world and the sentences are mostly new. You have to learn the patterns underneath. Grammar, sure. But also: that Paris goes with France, that a question wants an answer, that a story has a shape, that code has syntax, that "the opposite of hot is ___" wants "cold."
None of that gets programmed in. It's the residue of getting really, really good at one narrow game, played a staggering number of times. The model isn't told what a fact is. It just learns that certain words reliably follow certain others, and "facts" are one of the patterns that fall out.
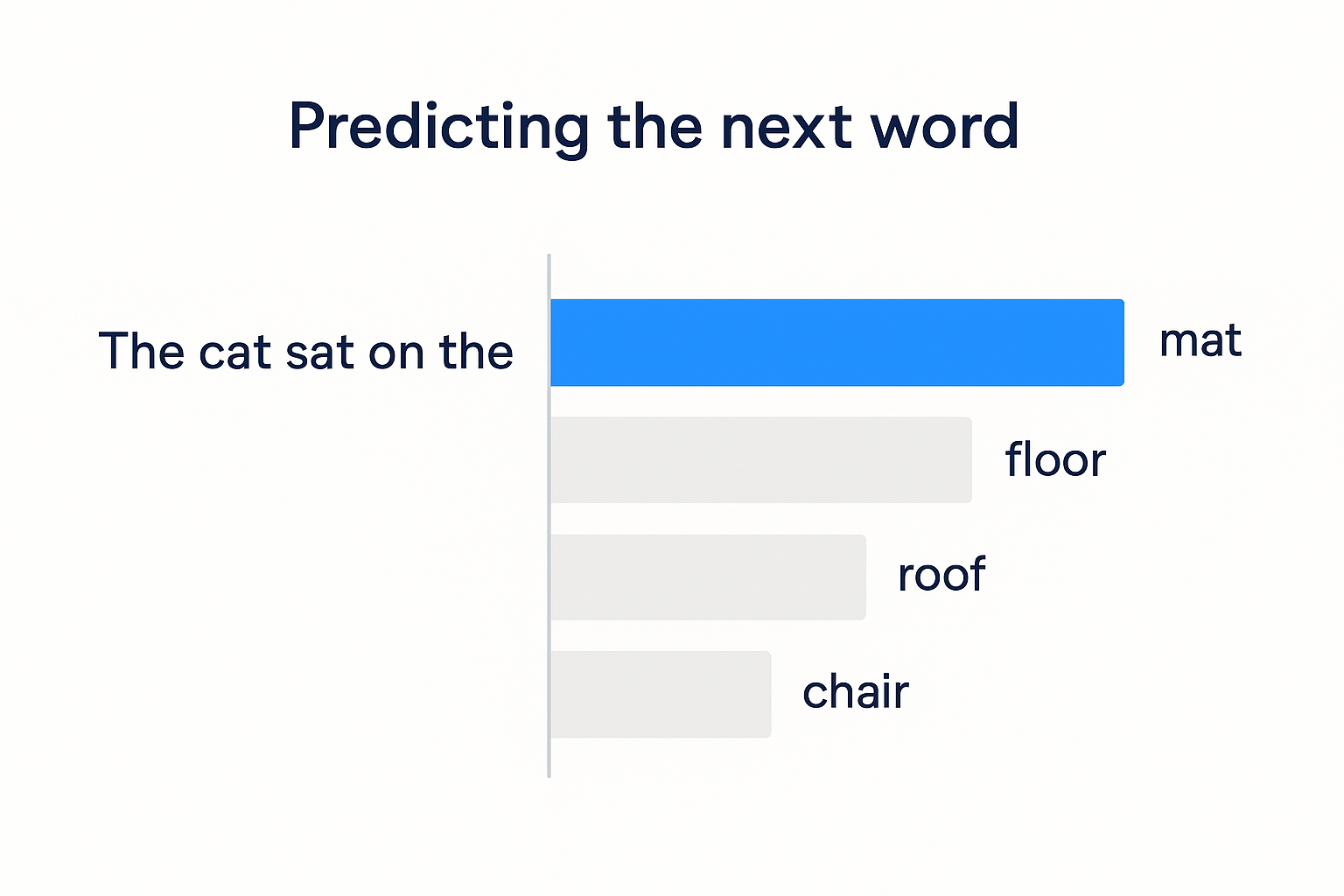
So when you ask a model the capital of France, it isn't looking anything up. It's completing a pattern. "The capital of France is ___" has, in nearly all the text it ever saw, been followed by "Paris." So that's what it predicts. Confidently. Every time.
Hold onto that, because it's also exactly why these models make things up, a topic we get to in part three. The same machinery that nails the capital of France will, just as confidently, complete a pattern that happens to be wrong. It doesn't know the difference. It was never checking truth. It was always just predicting the next word.
So does it understand?
This is where people draw battle lines, and honestly, I think it's the wrong question.
Does a model "understand" the way you do, with intentions, beliefs, a model of the world it's accountable to? No. It has no idea what it's saying. It has no stake in whether it's right.
But "it's just autocomplete, it understands nothing" undersells it too. To predict that well, it built up something real: a dense web of statistical relationships between concepts that is genuinely useful, that captures a huge amount of how we actually use language. Call it understanding or don't, the capability is there, and it's not fake.
The practical move is to stop arguing about the word and start respecting the shape of the thing. It is astonishingly capable at completing patterns it has seen. It has no built-in sense of truth, no memory beyond what you show it, and no way to know when it's wrong. That combination is the whole story: the power and the failure modes come from the same place.
Get that, and you're already ahead of most people talking confidently about AI. Next, we open up the transformer itself and look at the three moves that make it work: tokens, embeddings, and attention.